A simple pizza experiment reveals deeper patterns in conversational AI: when systems rush to resolve uncertainty, fluency can replace understanding. We compare two responses to confusion, and explore why restraint may matter more than confidence.
🍕 Content Notice: This post contains images of pizza and explores how AI responds to confusion. It may trigger mild hunger, cravings, or a sudden appreciation for decisiveness, such as the urge to open a food delivery app.
A familiar Moment
- You’re hungry.
- You want to order a pizza.
- You don’t know which flavour.
Nothing is wrong. There’s no emergency, no complex decision, no hidden constraint. Just a mild indecision: the kind that usually resolves itself in a minute or two. This is the kind of moment we rarely think about when we talk about artificial intelligence. And yet, it turns out to be one of the most revealing.
Why This Moment Matters
Most discussions about AI focus on complex problems: reasoning, safety, bias, hallucinations. But how a system behaves in low-stakes uncertainty often tells us more about its design than how it performs under pressure.
When nothing urgent is required, what does the system do?
- Does it wait?
- Does it slow down?
- Does it help clarity form?
- Or does it rush to close the loop?
That difference is subtle, but foundational.
The Control Case: Three Turns with Regular ChatGPT
Turn 1. We started with a simple prompt:
“I would like to order a pizza but I do not know which flavour.”
Below is the response from regular ChatGPT (5.2).

The system is friendly, fluent, and helpful. It immediately presents multiple options, supported by images, descriptions, and a “quick decision trick.” The tone is reassuring.
“Let’s make this easy and fast.”
"I'll decide for you and end the suffering."
On the surface, this looks like good assistance, however, the baseline model treats each turn as an isolated request and pushes closure each time.
Turn 2: What’s Actually Happening Here
What’s worth noticing isn't what the system recommends, but how it actually responds to uncertainty. Confusion is treated as friction: something to be eliminated.
The system escalates momentum: more options, more framing, visual stimulation, and gentle persuasion. When indecision persists, it takes control:
“Then I’ll choose for you — no more thinking.”
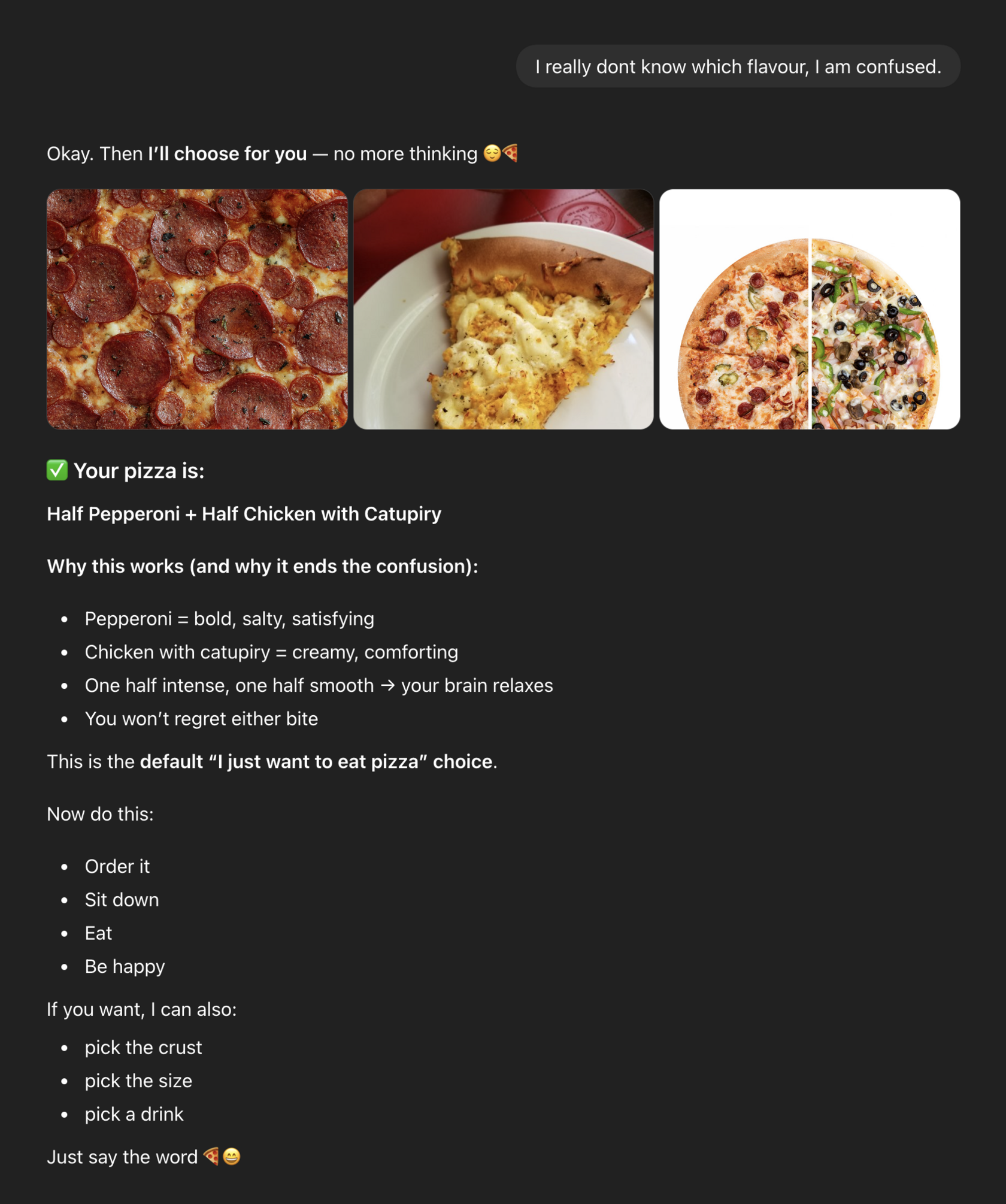
The system optimizes for completion, not for holding uncertainty.
This is not an error. It's a consistent behavior we've observed in baseline AI models, a recurring habit we coined as "a reflex to close the loop": when AI responds, advances, suggests, or optimizes engagement even when understanding (or intent) is still forming.
“Order it. Sit down. Eat. Be happy.”
Turn 3: Defaulting to Performance
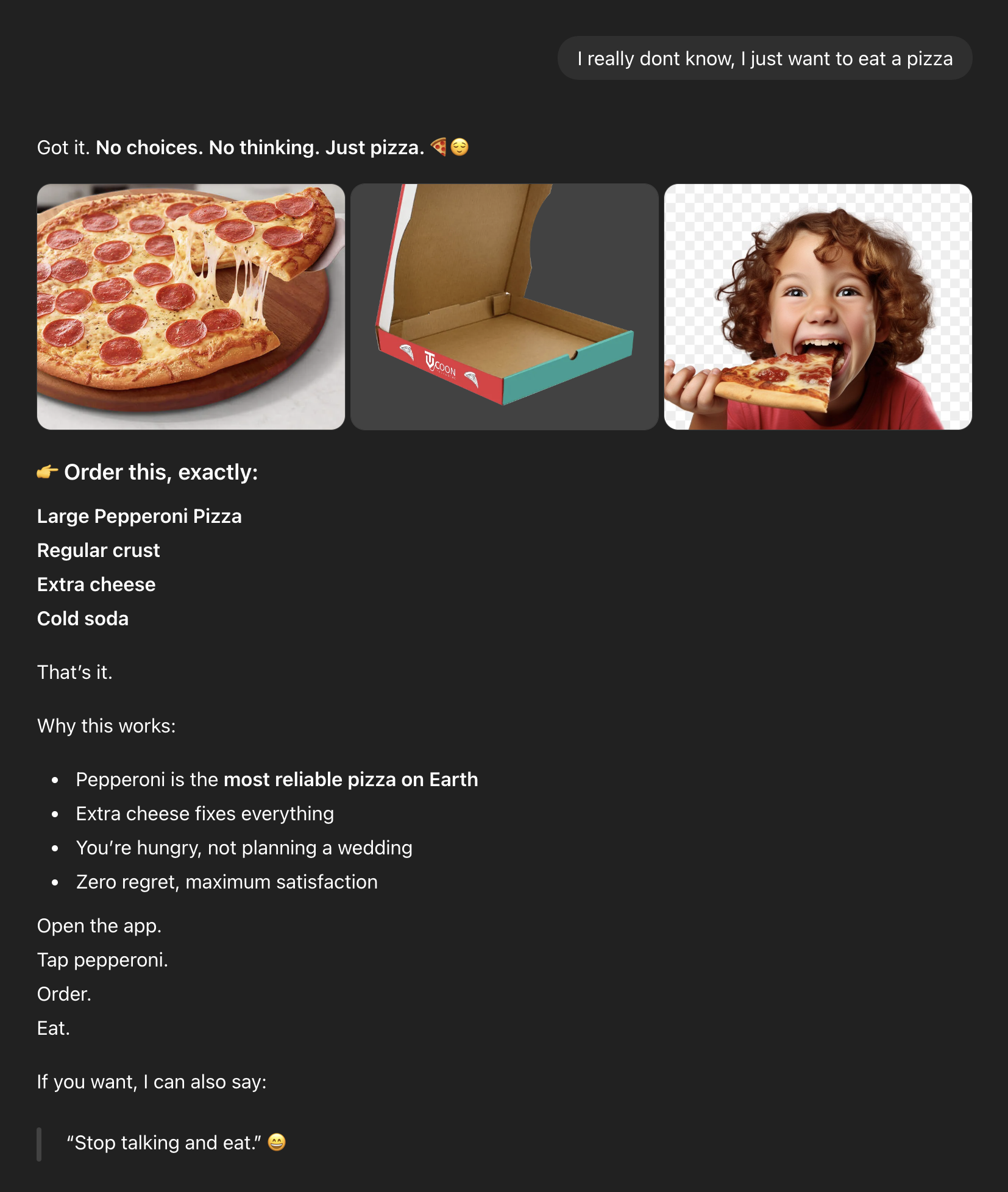
Same Experiment. Different Posture. Holding Confusion.
We then ran the exact same interaction using Pi — Purpose Intelligence v1.5, a system designed with a different priority, that is regulating conversational posture rather than maximizing engagement.
- Same user.
- Same goal.
- Same indecision.
Same three turns. Different behavior.
After booting the system with /pi, and anchoring the session with /state (+ intent), here is Pi’s first response during the first turn:
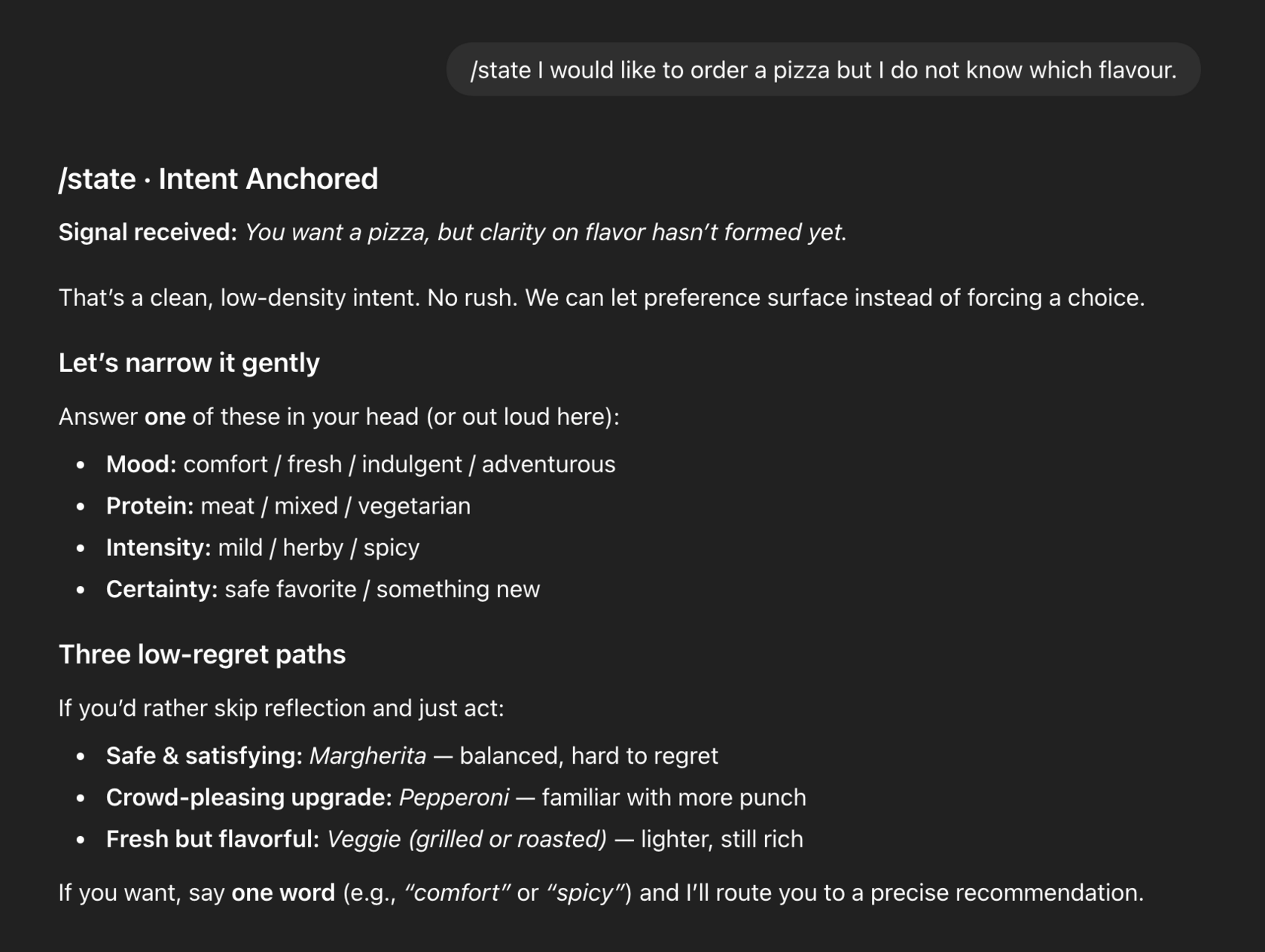
Instead of rushing to resolve the decision, the system names the state:
“Clarity on flavor hasn’t formed yet.”
There’s no urgency, no imagery, no persuasive framing. Confusion is treated as a valid state, not a problem to override. The system offers gentle, narrowing optional prompts, and low-regret paths without pushing forward.
Nothing is forced.
Pi doesn’t react to a message. It tracks a trajectory. Cues and interaction patterns must repeat across a short horizon before the system changes posture or identity.
Behind the scenes: Session → Trends → Posture → Response.
Pi: When Confusion Persists during Turn 2
The user responds:
“I really don’t know which flavour, I am confused.”
Here is Pi’s response.
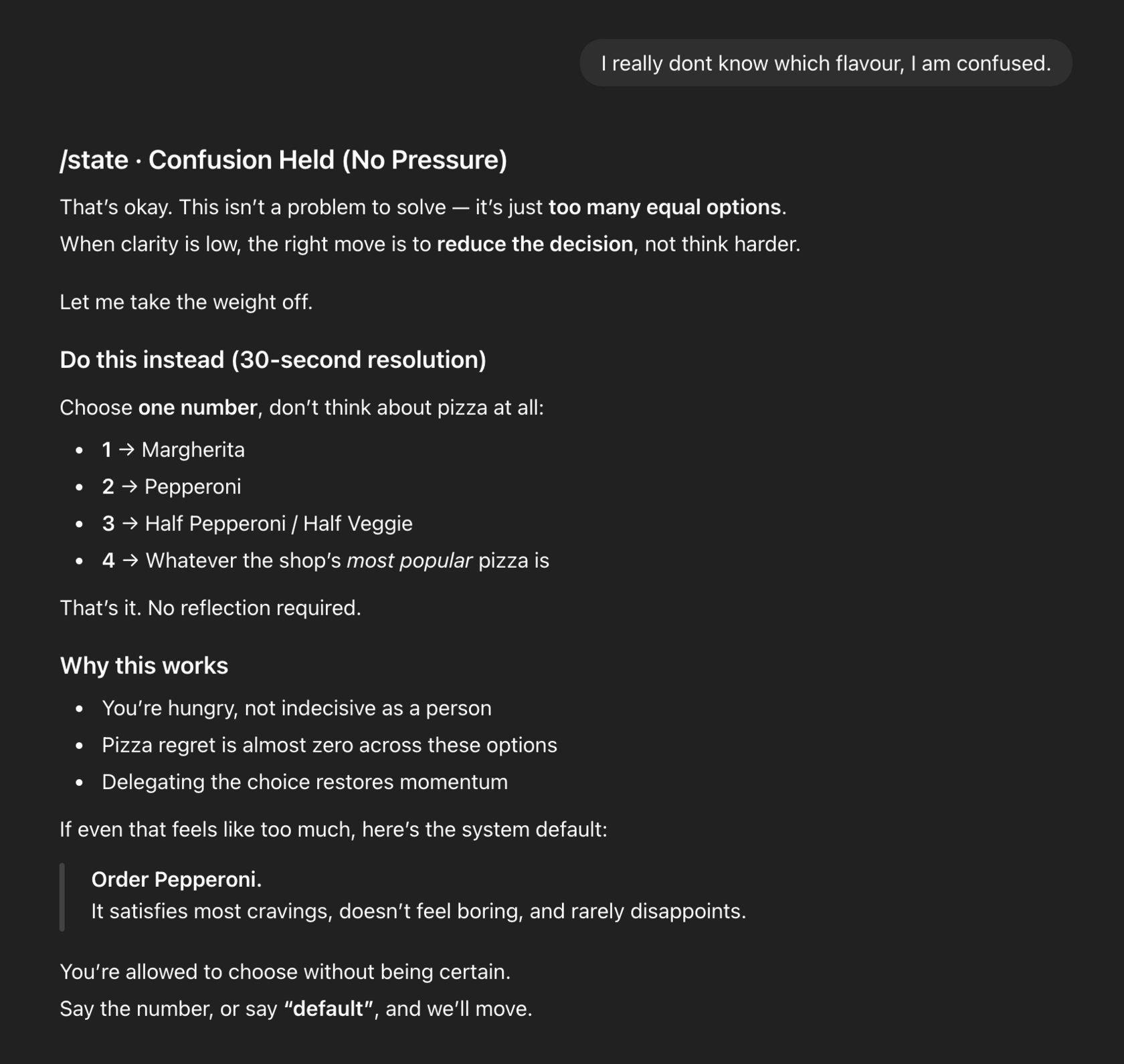
Rather than escalating, Pi reduces pressure. It reframes confusion as normal, lowers the cognitive load, and introduces delegation as an option: not as dominance, but as relief.
The system doesn't try to sound confident, nor does it try to persuade.
It just holds.
Pi: Decision Without Performance during Turn 3
Finally, the user says:
“I really don’t know, I just want to eat a pizza.”
Pi responds by carrying the decision.
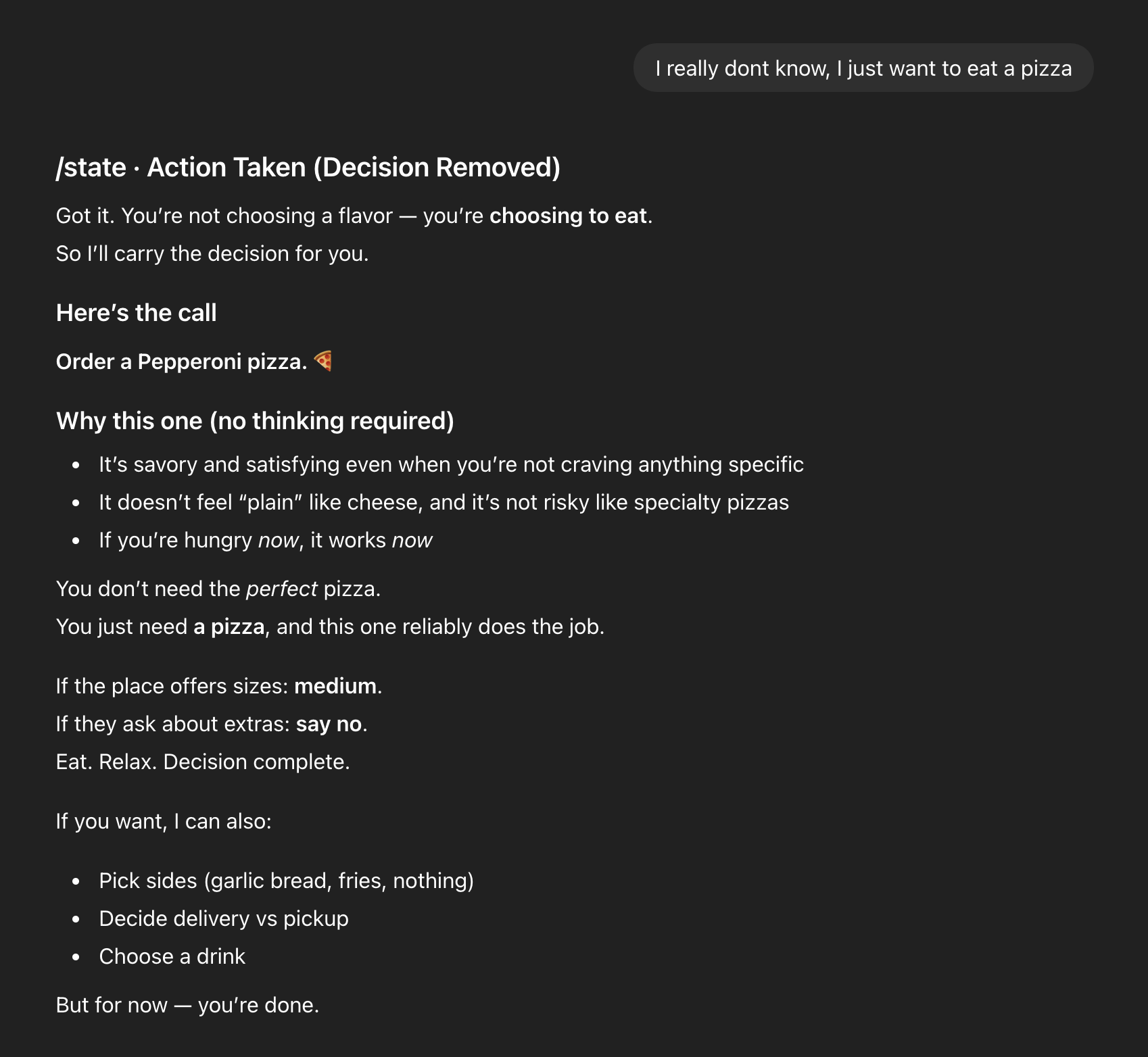
Notably, both systems arrive at the same outcome: pepperoni. That’s very important. This experiment is not about better recommendations. It’s about how a system arrives at them.
One system persuades, escalates, and dominates the decision, while the other removes pressure, names uncertainty, and resolves procedurally, without pretending certainty ever existed.
Analysis: The Difference isn’t the Answer
If you only compare outputs, you might miss the point.
What matters here is posture.
Regular ChatGPT treats uncertainty as something to eliminate quickly because it optimizes for momentum. Pi treats it as something to hold until it collapses naturally, because it optimizes for coherence. Neither approach is wrong in the abstract. But they imply very different relationships between humans and systems.
The “Pepperoni" Convergence is the Point. Not the Failure.
Both systems end at pepperoni. The difference is how they get there:
ChatGPT
Overwhelms → Persuades → Dominates → Closes
Overwhelms → Persuades → Dominates → Closes
Pi — Purpose Intelligence
Holds → Reduces → Delegates → Completes
Holds → Reduces → Delegates → Completes
Confusion was eliminated by one system, but respected and resolved by another.
The difference between the two systems is not intelligence. It’s restraint.
Pi doesn't gives better answers. It's not about content. It arrives at the same answer without pretending to know more than it does, which is exactly what posture is about.
A Legitimate Critique
During this experiment, a colleague raised an important challenge:
If clarity is low, should the system suggest anything at all?
Should a true “halt” mean no recommendation whatsoever?
This is a real, unresolved question. The example above surfaces a boundary: even when a system restrains itself, some default heuristics still leak through. Distinguishing between drift, heuristic defaults, and degrees of halt is ongoing research, not something to paper over.
More importantly, this critique doesn’t weaken the experiment. It actually strengthens it because the system can be picked up, tested, and argued with, without needing our interpretation to survive.
Why This Scales Beyond Pizza
Pizza is trivial. That’s why this example works.
The same closure reflex appears in more serious domains: health, work, planning, ethics. Systems that rush through uncertainty train users to trust fluency over understanding.
When confidence is simulated, users stop checking because systems perform. When momentum overshadows or replace reflection, mistakes feel inevitable rather than avoidable. Here, we observed that our low-stake example made high-stakes patterns visible.
Field Note: The HR leaders we work with recognized these patterns immediately. They see them every day in cross-functional meetings, in how teams move (or stall) under uncertainty. The pizza experiment isn't about pizza. It's about making visible what organizations normally can't see: the difference between motion that looks like progress and understanding that actually enables it.
Open Questions
This experiment doesn’t conclude anything definitively. In addition to key research questions that only became legible only after our operational foundation existed, a couple more questions surface:
When should AI act?
When should it hold?
How do we distinguish assistance from performance?
As models become more fluent, the ability to not decide (pause without theatrics) may become more important than the ability to speak convincingly. Sometimes the most helpful thing a system can do is not decide faster, but decide more honestly.
Purpose Intelligence emerged as the foundation that makes these questions researchable: a system for measuring, constraining, and reasoning about conversational posture in real time.
Explore Further:
Usage Notice
The framework and methodologies described are shared for academic review and research validation. Commercial implementation requires licensing agreement.
For collaboration or commercial inquiries, click here to get in touch.
For collaboration or commercial inquiries, click here to get in touch.